----
지금까지 RAG 가 무엇인지 보았고, RAG를 위해 필요한 embedding을 학습했다
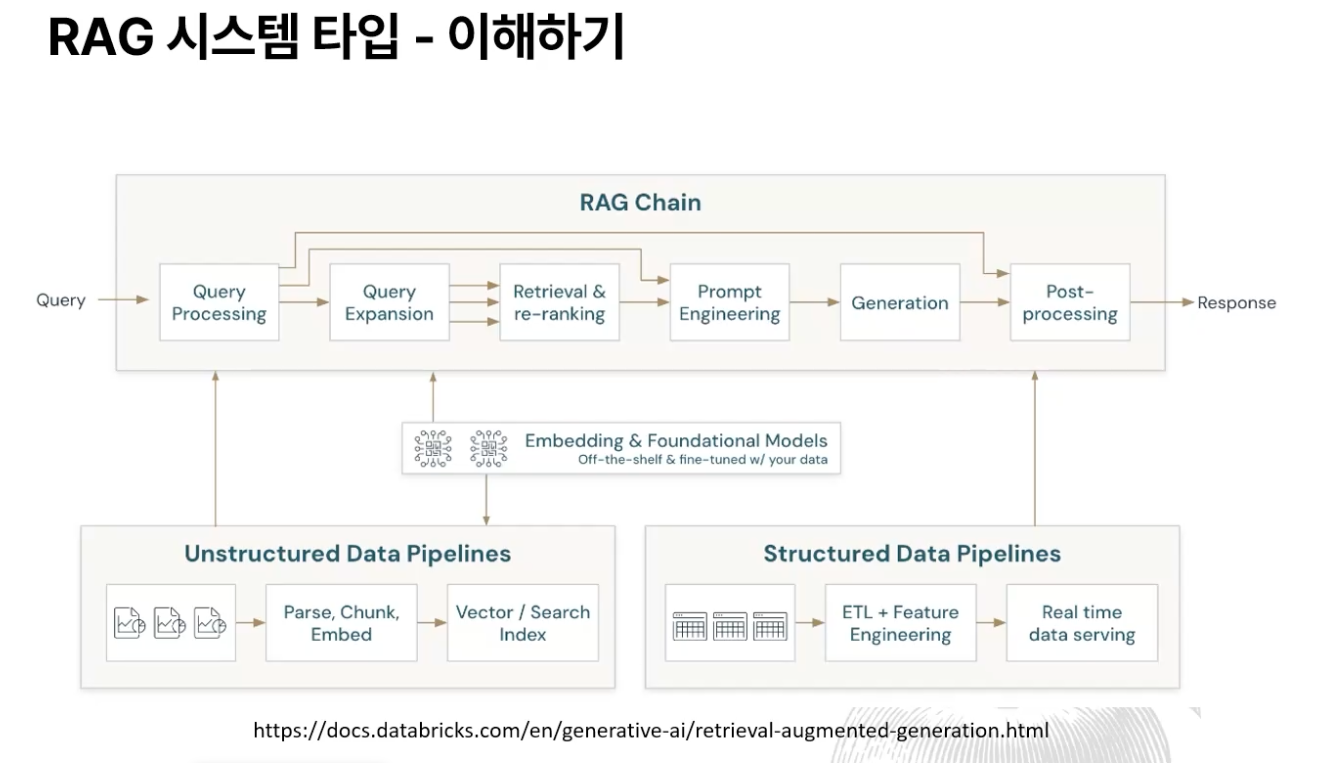
RAG 아키텍처 타입
질문이 들어옴 -> 답변을 열심히 찾아서 정리해서 옴 -> 아나운서에게 이거 보고 답변하라고 함
"답변에 필요한 정보를 찾아서"
"정리해서"
- 물어볼만한 답변을 밀 ㅣ폴더에 잘 정리해 두기
- 사연도 정리해두기
- 유툽 댓글도 리서치 해서 잘 정리해두기
- 다시 한 번 추출해서 정리하기
RAG 아키텍쳐 샘플


---
기존에 가지고있는 데이터를 Json으로 만들어서 Vector DB 형태로도 사용 함
---
Grounding (얼마나 사실에 기반하는지) 하기 위해 많이 사용하는 것이 RAG, FineTuning
Fine Tuning 미세 조정



ex) Oracle 로 하면 잘 되는데 Postgresql로는 안돼요..
ex) FineTuning을 많이하면 모델의 기본 기능이 저하될 수도 있음
==> RAG 와 파인튜닝은 상호 보완적인 기법이다
==> 최신 응답, 최소한의 허위 생성, 적응령을 위해 ㄲㅁㅎfmf tjsxor
==> 충분한 훈련 데이터가 있는 특정 도메인에서 우수한 정확성을 위해 파인튜닝
==> 같이 사용하여 하이브리드 모델을 생성
ex) 복약지도 - 약의 대한 내용은 자주 바뀌지 않고 질문과 답이 확실한 경우 FineTuning을 사용하고, 특정 환자에게 복약 지도를하는 것은 RAG를 사용한다
FineTuning이 많이 쓰이는 분야
== 정해지고 반복될 때,
새로운 장르, 혹은 분야
- 의료/과학/보험/자동차/리테일 등 그 분야 내 고유의 언어 혹은 문제 풀이 방식이 있을 때
특정한 일을 수행 할 때 퍼포먼스 올리기
- 번역 혹은 특정한 컨텐츠를 생성할 때
아웃풋 방시이 특수할 때
- 코드 생성, 텍스트의 분위기 설정, 디테일 레벨 설정 등등
새로운 데이터에 적응 할 때
- 고객지원, 번역, 텍스트 감정분석, 특정 분야 내의 질답 FAQ
파인튜닝이 별로 일 때
- 데이터셋이 적을 때
- 원 모델의 훈련 데이터와 내가 쓰고 싶은 시나리고가 아주 다른 경우 파인튜닝으로 극복 안 되는 경우가 많음
- 모델을 자주 업데이트 혹은 수정해야함
- 더 단순한 방법이 있을 때..

----
https://velog.io/@adc0612/stateful%EA%B3%BC-stateless-%EC%B0%A8%EC%9D%B4-7tfkp7a4
stateful과 stateless 차이
클라이언트-서버 관계에서 서버가 클라이언트의 상태를 보존함을 의미한다.클라이언트의 이전 요청이 서버에 잘 전달되었을 때, 클라이언트의 다음 요청이 이전 요청과 관계가 이어지는 것을
velog.io
[Stateful/Stateless] Stateful vs. Stateless 서비스와 HTTP 및 REST
Contents 0. Prologue 1. Stateful Service 2. Stateless Service 3. Why Stateless Service 4. Stateless Service 및 HTTP, 그리고 REST Stateful/Stateless 서비스의 개념을 알아보고, 이를 바탕으로 Stateless 서비스가 최근 각광 받는 이
5equal0.tistory.com
---
< 시스템에 LLM 을 활용하는 방법 / LLM 활용 법, LLM 비즈니스, LLM 난이도 별 서비스 >
서비스가 복잡할 수록
전문 용어가 많거나, 데이터가 많지 않은 경우 -> RAG를 쉽게 구현 가능한 경우..
실시간이 중요한 경우
정확도가 중요한 경우 ( 메뉴 추천 같은 경우는 정확도 필요 없으니까... )
multi-turn을 제공해야할 때..
사용자가 많을 수록
LLM 도입에 고려해야할 것이 많아진다. 시간이 소요된다. 복잡해진다.


---

---
http://www.ktword.co.kr/test/view/view.php?no=4086
결정론적
Deterministic, Nondeterministic 결정론적, 비결정론적(2023-05-30)결정론적 모델 비결정론적 모델 비교, Deterministic Model, 결정론적 모델, 결정적 모형, Deterministic, 결정 신호, 확정 신호, Statistical Mode, 통
www.ktword.co.kr
---
언어모델은 동일한 질문도 다양하게 질문할 수 있기 때문에, TC가 다양하여 답변의 질을 확실하게 테스트 할 수가 없다.
RAG가 있다던지하면 Data retrieval 스텝별로 테스트도 필요하다, 디자인할 때부터 데이터 소스가 여러 곳이라면 Unit Test 방법을 고안하는 것이 좋다.
---
< LLM 디자인의 기본 >
1. LLM 사용 최소화
- 최대한 LLM 사용을 줄이고, 가능한 경우 결정론적 프로그래밍 언어 사용
- 비용 절감 : LLM은 계산 비용이 많이 드는 반면, 결정론적 언어는 효율적
- 속도 향상 : LLM 추론 속도는 느릴 수 있지만, 결정론적 언어는 빠르게 실행
- 테스트 용이성
- 유지 보수 용이성 : 결정론적 코드는 이해하고 유지 관리하기 쉬움
2. 처음부터 확장성 및 안정성 고려
- 시스템 설계 단계부터 확장성과 안정성을 고려해야 함 / 안정적인 API 디자인!!
- 느린 속도
- 높은 비용
- 예측 불가능한 결과
- 상용 서비스 제공 시 중
3. 응답 품질 확실한 테스트
- 특히 민감한 분야 ( 의료, 정부, 볍률, 금융 ) 시스템 응답 품질 엄격하게 테스트 해야함
- 이유 : 부정확한 정보, 편향된 겨로가, 비윤리적 결과, 법적 책임
4. RAI, 데이터 개인 정보 보호, 보안 고려
- 책임 있는 AI(RAI), 데이터 개인 정보 보호, 보안은 LLM 시스템 설계 필수 요소
- 윤리적 문제 : 편향 ,차별, 악용 등 윤리적 문제 발생 가능성
- 개인 정보 침해
- 시스템 해킹 : 보안 취약점 악용시 시스템 손상 및 데이터 유출 가능성
5. 운용 비용 고려
- 파인 튜닝, RAG 시스템 등등
6. LLM 디자인 간소화하기
1) 싱글턴 vs 멀티턴
- 작업 유형 vs 데이터 양 vs 사용자 경험 을 고려하여 정하기
2) 데이터 소스 숫자 줄이기 ( 데이터 출처 )
3) 사용자 세선 서포트 최소화 하기
--
어떤 모델을 사용할 수 있을까 고민하기 전에
어떤 데이터가 있는지 데이터 서빙부터 시작하자.
'기타내용' 카테고리의 다른 글
| 패스트캠퍼스 AI 개발자의 LLM 마스터 클래스(4) (0) | 2025.02.01 |
|---|---|
| 패스트캠퍼스 AI 개발자의 LLM 마스터 클래스(3) (1) | 2025.01.31 |
| 패스트캠퍼스 ChatGPT와 함께 월 100만원 수익 블로그 만들기 (2) (1) | 2025.01.30 |
| OpenAI Platform - API, Playground 사용하기 (0) | 2025.01.30 |
| 패스트캠퍼스 AI 개발자의 LLM 마스터 클래스(2) (0) | 2025.01.28 |